架构 - 发展历程
文章来源
- 作者:李智慧
- 来源:《大型网站技术架构》
大型网站系统
- 高并发,大流量
- 需要面对高并发用户,大流量访问。Google 日均 PV 35 亿(PageViews),日 IP 访问数 3 亿;腾讯 QQ 的最大在线用户数 1.4 亿(2011年数据)。
- 高可用
- 系统 7 x 24 小时不间断服务。
- 海量数据
- 需要存储、管理海量数据,需要使用大量服务器。Facebook 每周上传的照片数量接近 10 亿,百度收录的网页数目有数百亿,Google 有近百万台服务器为全球用户提供服务。
- 用户分布广泛,网络情况复杂
- 许多大型互联网站都是为全球用户提供服务的,用户分布范围广,各地网络情况千差万别。在国内,还有各个运营商网络互通难的问题。
- 安全环境恶劣
- 由于互联网的开放性,使得互联网站更容易受到攻击,大型网站几乎每天都会被黑客攻击。
- 需求快速变更,发布频繁
- 和传统软件的版本发布频率不同,互联网产品为快速适应市场,满足用户需求,其产品发布频率极高。一般大型网站的产品每周都有新版本发布上线,中小型网站的发布更频繁,有时候一天会发布几十次。
- 渐进式发展
- 几乎所有的大型互联网网站都是从一个小网站开始,渐进地发展起来的。Facebook 是扎克伯格同学在哈佛大学的宿舍里开发的;Google 的第一台服务器部署在斯坦福大学的实验室;阿里巴巴是在马云家的客厅诞生的。好的互联网产品都是慢慢运营出来的,不是一开始就开发好的,这也正好与网站架构的发展演化过程对应。
架构演进
大型网站的技术挑战主要来自于庞大的用户,高并发的访问和海量的数据,任何简单的业务一旦需要处理数以P计的数据和面对数以亿计的用户,问题就会变得很棘手。大型网站架构主要就是解决这类问题。
架构选型是根据当前业务需要来的,在满足业务需求的前提下,既要有足够的扩展性也不能过度设计,每次的架构升级都是为了解决系统瓶颈而做的。
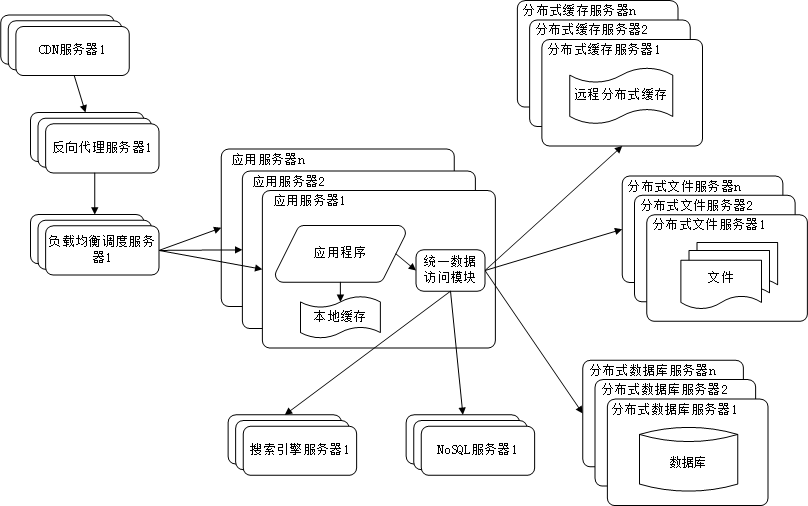
初始阶段的网站架构
初始阶段都比较简单,通常一台服务器就可以搞定一个网站了, 即将应用程序、数据库、文件等所有资源都存放在一台服务器上,可以使用 LAMP 架构(Linux操作系统 + Apache网站服务器 + MySQL数据库服务器 + PHP网页编程语言) 。
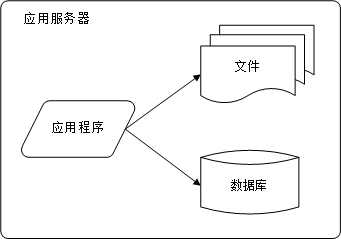
应用服务和数据服务分离
随着网站业务的发展,一台服务器逐渐不能满足需求 ———— 采用应用和数据分离,整个网站开始使用三台服务器:应用服务器、文件服务器和数据服务器。

使用缓存改善网站性能
根据二八定律:80%的业务访问都会集中在20%的数据上。 可以通过增加缓存来改善网站的性能。
主要存在两种缓存方式:
- 应用服务器的本地缓存
- 分布式缓存服务器的远程缓存

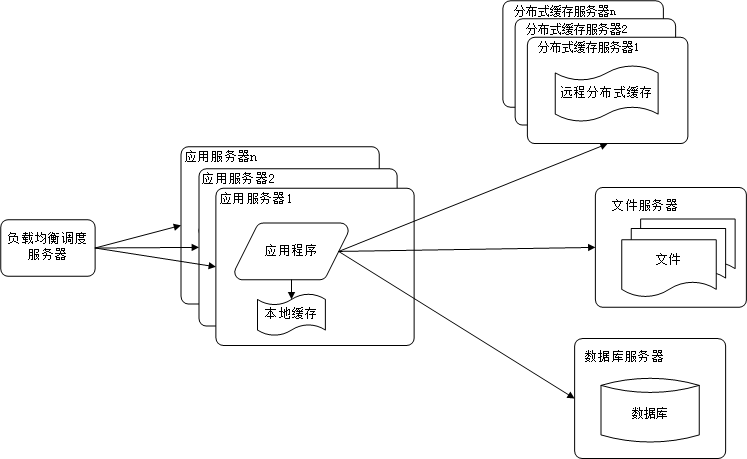
使用应用服务器集群改善网站的并发处理能力
因为单一应用服务器能够处理的请求连接有限,在网站访问高峰时期,应用服务器会成为整个网站的瓶颈。可以通过增加服务器数量的方式,分担原有服务器的访问压力。通过负载均衡调度服务器,可将来自浏览器的访问请求分发到应用的集群中的任何一台服务器上。
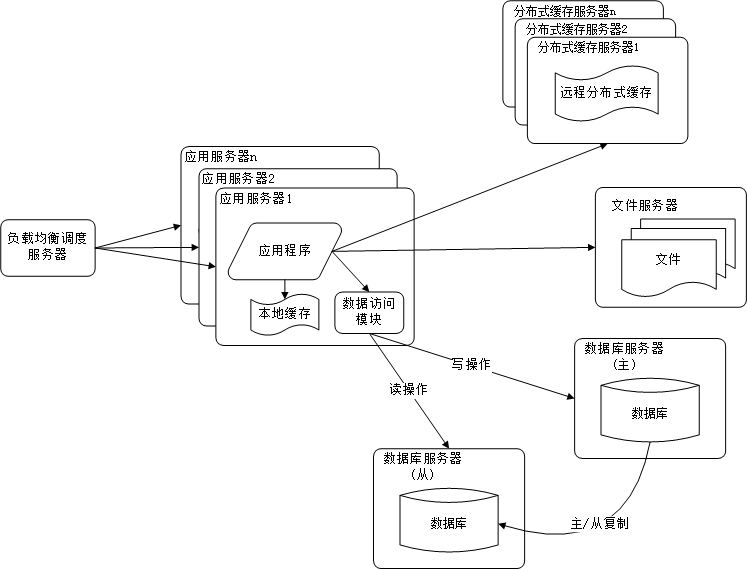
数据库读写分离
当用户达到一定规模后,数据库因为负载压力过高而成为网站的瓶颈。而目前主流的数据库都提供主从热备功能,通过配置两台数据库主从关系,可以将一台数据库的数据更新同步到另一台服务器上。网站利用数据库这一功能实现数据库读写分离,从而改善数据库负载压力。
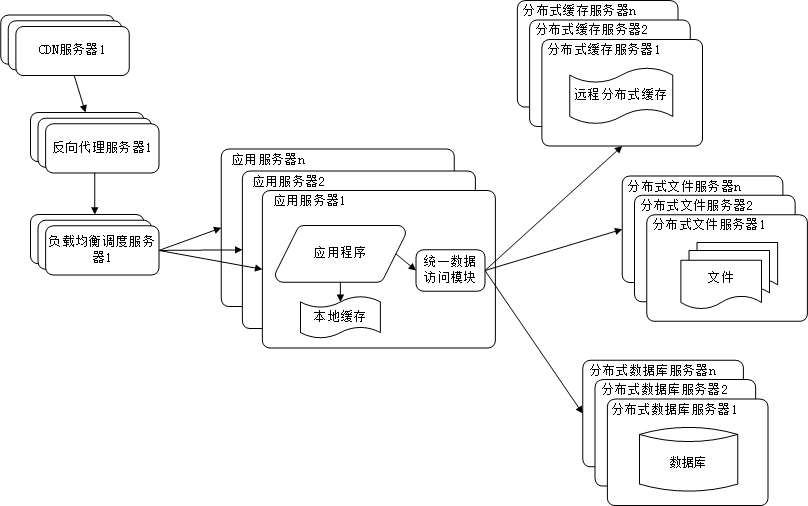
使用反向代理和CDN加上网站相应
为了提供更好的用户体验,网站需要加速网站的访问速度,主要手段有使用CDN和反向代理。
CDN和反向代理的基本原理都是缓存,区别在于:
- CDN部署在网络提供商的机房,使得用户在请求网站时,可以从距离自己最近的网络提供商机房获取数据;
- 反向代理是部署在网站的中心机房,当用户请求到达中心机房后,首先访问的反向代理,如果反向代理缓存着用户请求的资源,则直接返回给用户。
使用CDN和反向代理的目的都是尽早返回数据给用户,一方面加快用户访问速度,另外一方面也减轻后端服务器的负载压力。

使用分布式文件系统和分布式数据库系统
任何强大的单一服务器都满足不了大型网站持续增长的业务需求。分布式数据库时网站数据库拆分的最后手段,只用在单表数据规模非常大的时候才使用。不到不得已时,网站更常用的数据库拆分手段是业务拆分,将不同业务的数据部署在不同的物理服务器上。
使用NoSQL和搜索引擎
搜索引擎也基本已经形成现在大型网站必须提供的功能了,网站需要采用一些非关系数据库技术如NoSQL和非数据库查询技术如搜索引擎。
业务拆分
大型网站为了应对日益复杂的业务场景,通过使用分而治之的手段将真个网站业务拆分成不同的产品线。 具体到技术上,也会根据产品线话费,将一个网站拆分成许多不同的应用,每个应用独立部署维护。应用之间可以通过超链接建立管理,也可以通过消息队列进行数据分发,当然最多的还是通过访问同一个数据存储系统来构成一个关联的完整系统。

分布式服务
由于每一个应用系统都需要执行许多相同的业务操作,比如用户管理,session管理,那么可以将这些公用的业务提取出来,独立部署。

电商系统架构演进
具体以电子商务网站为例, 展示web应用的架构演变过程:
- 单体应用
- web应用服务器横向扩展
- 数据库读写分离
- 业务垂直拆分(快速迭代子模块)
- 使用CDN来缓存信息,加速访问
- 分库分表设计
- 考虑容灾场景,同城双机房
- 单元化
1.0时代

一个web项目里包含了所有的模块,一个数据库里包含了所需要的所有表。
基于这种框架下网站访问量增加时,面临的困难:
- 应用服务器连接数遇到瓶颈,
- tomcat连接数不能无限增加
- 线程数上限受进程内存大小、CPU内核数等因素影响
- 当线程数到达一定数时候,线程上下文的切换对性能的损耗会越来越严重,响应会变慢。
- 解决方案:
- 对web应用服务器进行横向扩展
2.0时代

随着网站访问量继续增加,继续增加应用服务器数量已经无法解决问题:
- 数据库成了制约性能的瓶颈:
- 数据库的最大连接数是有限的
- 例如数据库的连接数设置8000,如果每个应用服务器与数据库的初始连接数设置40,那么200台web服务器是极限。
- 并且随着连接数增加,数据库的读写压力增大,耗时增加
- 当单表数量过大时,对该表的操作耗时会增加,索引优化也是缓兵之计
- 数据库的最大连接数是有限的
- 解决方案:
- 采用主从方式进行读写分离的方案,并且引入缓存机制来降低读流量。
3.0时代
读写分离

所有业务集中在一个项目里。项目维护、快速迭代问题会越来越严重,单个模块的开发都需要发布整个项目,项目稳定性也受到很大挑战。
- 解决方案:
- 业务的垂直拆分:按模块划分应用。
业务垂直拆分

为了进一步提升用户体验,加速用户的网站访问速度。
- 解决方案:
- 使用CDN来缓存信息,用户会访问最近的CDN节点来提升访问速度。
使用CDN来缓存信息

随着业务量增大,一些核心系统数据库单表数量达到几千万甚至亿级,这时候对该表的数据操作效率会大大降低,并且虽然有缓存来抗读的压力,但是对于大量的写操作和一些缓存miss的流量到达一定量时,单库的负荷也会到达极限。
- 解决方案:
- 采用分库分表:解决大数据量下的数据访问。
分库分表架构

随着流量的进一步增大,这时候系统仍然会有瓶颈出现,以订单系统为例:
- 解决方案:
- 采用同城双机房的方式:机房之间用专线链接,同城跨机房质检的延时在几毫秒,以解决单个机房的机器的访问压力。
同城双机房

由于数据库主库只能是在一个机房,所以仍然会有一半的数据库访问是跨机房的,虽然延时只有几毫秒,但是一个调用链里的数据库访问太多后,这个延时也会积少成多。其次这个架构还是没能解决数据库连接数瓶颈问题
随着应用服务器的增加,虽然是分库分表,但每增加一台应用服务器,都会与每个分库建立连接,比如数据库连接池默认连接数是40,而如果mysql数据库的最大连接数是8000的话,那么200台应用服务器就是极限。当应用的量级太大后,单个城市的机器、电、带宽等资源无法满足业务的持续增长
- 解决方案:
- 考虑SET化架构,也就是单元化架构,大体思路就是将一些核心系统拆成多个中心,每个中心成为一个单元,流量会按照一定的规则分配给每个单元,这样每个单元只负责处理自己的流量就可以了。每个单元要尽量自包含、高内聚。这是从整体层面将流量分而治之的思路。
单元化

从上面的架构图里能看到,流量从接入层按照路由规则(比如以用户ID来路由)路由到不同单元,每个单元内都是高内聚,包含了核心系统,数据层面的分片逻辑是与接入层路有逻辑一致,也解决了数据库连接的瓶颈问题,但是一些跨单元的调用是无法避免的,同时也有些无法拆分的业务需要放在中心单元,供所有其他单元调用。