libco -协程学习
参考资料
libco简介
libco是微信后台大规模使用的c/c++协程库,2013年至今稳定运行在微信后台的数万台机器上。
libco通过仅有的几个函数接口 co_create/co_resume/co_yield 再配合 co_poll,可以支持同步或者异步的写法,如线程库一样轻松。同时库里面提供了socket族函数的hook,使得后台逻辑服务几乎不用修改逻辑代码就可以完成异步化改造。
hook函数补充介绍:
钩子(Hook),是Windows消息处理机制的一个平台,应用程序可以在上面设置子程以监视指定窗口的某种消息,而且所监视的窗口可以是其他进程所创建的。当消息到达后,在目标窗口处理函数之前处理它。钩子机制允许应用程序截获处理window消息或特定事件。
钩子实际上是一个处理消息的程序段,通过系统调用,把它挂入系统。每当特定的消息发出,在没有到达目的窗口前,钩子程序就先捕获该消息,亦即钩子函数先得到控制权。这时钩子函数即可以加工处理(改变)该消息,也可以不作处理而继续传递该消息,还可以强制结束消息的传递。
2
libco的特性
- 无需侵入业务逻辑,把多进程、多线程服务改造成协程服务,并发能力得到百倍提升;
- 支持CGI框架,轻松构建web服务(New);
- 支持gethostbyname、mysqlclient、ssl等常用第三库(New);
- 可选的共享栈模式,单机轻松接入千万连接(New);
- 完善简洁的协程编程接口
- 类pthread接口设计,通过co_create、co_resume等简单清晰接口即可完成协程的创建与恢复;
- __thread的协程私有变量、协程间通信的协程信号量co_signal (New);
- 语言级别的lambda实现,结合协程原地编写并执行后台异步任务 (New);
- 基于epoll/kqueue实现的小而轻的网络框架,基于时间轮盘实现的高性能定时器;
导论
libco是一种非对称协程(asymmetric coroutines),是跟一个特定的调用者绑定的,协程让出CPU时,只能让回给原调用者。
对称协程(symmetric coroutines)则不一样,启动之后就跟启动之前的协程没有任何关系了。
不对称体现在:
- 调用方式:程序控制流转移到被调协程时使用的是 call/resume 操作,而当被调协程让出 CPU时使用的却是 return/yield 操作
- 地位:caller 与 callee 关系是确定的,不可更改的,非对称协程只能返回最初调用它的协程。
测试程序
生产者和消费者的例子:
#include <time.h>
#include <stdlib.h>
#include <iostream>
#include <vector>
#include <string>
#include "co_routine.h"
void* Producer(void* arg);
void* Consumer(void* arg);
struct stPara_t
{
// 条件变量
stCoCond_t* cond;
// 数据池
std::vector<int> vecData;
// 数据ID
int id;
// 协程id
int cid;
};
int main()
{
stPara_t p;
p.cond = co_cond_alloc();
p.cid = p.id = 0;
srand(time(NULL));
// 协程对象(CCB),一个生产者,多个消费者
const int nConsumer = 2;
stCoRoutine_t* pProducerCo = NULL;
stCoRoutine_t* pConsumerCo[nConsumer] = { NULL };
// 创建启动生产者协程
// 看源码可知该函数必返回0
co_create(&pProducerCo, NULL, Producer, &p);
co_resume(pProducerCo);
std::cout << "start producer coroutine success" << std::endl;
// 创建启动消费者协程
for (int i = 0; i < nConsumer; i++)
{
co_create(&pConsumerCo[i], NULL, Consumer, &p);
co_resume(pConsumerCo[i]);
}
std::cout << "start consumer coroutine success" << std::endl;
// 启动循环事件
co_eventloop(co_get_epoll_ct(), NULL, NULL);
return 0;
}
void* Producer(void* arg)
{
// 启用协程HOOK项
co_enable_hook_sys();
stPara_t* p = (stPara_t*)arg;
int cid = ++p->cid;
while (true)
{
// 产生随机个数据
for (int i = rand() % 5 + 1; i > 0; i--)
{
p->vecData.push_back(++p->id);
std::cout << "[" << cid << "] + add new data:" << p->id << std::endl;
}
// 通知消费者
co_cond_signal(p->cond);
// 必须使用poll等待
poll(NULL, 0, 1000);
}
return NULL;
}
void* Consumer(void* arg)
{
// 启用协程HOOK项
co_enable_hook_sys();
stPara_t* p = (stPara_t*)arg;
int cid = ++p->cid;
while (true)
{
// 检查数据池,无数据则等待通知
if (p->vecData.empty())
{
co_cond_timedwait(p->cond, -1);
continue;
}
// 消费数据
std::cout << "[" << cid << "] - del data:" << p->vecData.front() << std::endl;
p->vecData.erase(p->vecData.begin());
}
return NULL;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
创建协程,函数原型声明为:
int co_create( stCoRoutine_t **co,const stCoRoutineAttr_t *attr,void *(*routine)(void*),void *arg )
- co为出参,返回创建的协程对象
- attr为入参,指定创建协程的属性,本次使用默认属性,传空
- routine为入参,指定协程执行函数
- arg为入参,指定协程执行函数的参数
从函数结构可以看出co_create 和 pthread_create 用法相似:
#include <pthread.h>
int pthread_create(
pthread_t *restrict tidp, //新创建的线程ID指向的内存单元。
const pthread_attr_t *restrict attr, //线程属性,默认为NULL
void *(*start_rtn)(void *), //新创建的线程从start_rtn函数的地址开始运行
void *restrict arg //默认为NULL。若上述函数需要参数,将参数放入结构中并将地址作为arg传入。
);
2
3
4
5
6
7
跟 pthread 不太一样是,创建出一个协程之后,并没有立即启动起来;这里要启动协程,还需调用 co_resume() 函数。 最后,pthread 创建线程之后主线程往往会 pthread_join() 等等子线程退出,而这里的例子没有“co_join()”或类似的函数,而是主协程调用了一个 co_eventloop() 函数。
编译指令:
g++ mytest.cpp -o mytest -I./ -L./lib -lcolib -lpthread -ldl
测试程序是依赖co_cond_signal()、poll() 和 co_cond_timedwait() 来实现生产者和消费者的交替执行的。
协程控制块
与线程一样,协程也有属于自己的结构体。
协程控制块:
struct stCoRoutine_t
{
stCoRoutineEnv_t *env; //协程执行的环境
pfn_co_routine_t pfn; //待执行的协程函数
void *arg; //协程函数对应的参数
coctx_t ctx; //用于协程切换时保存 CPU 上下文(context)的;所谓的上下文,即esp、ebp、eip和其他通用寄存器的值。
char cStart; //状态和标志变量
char cEnd;
char cIsMain;
char cEnableSysHook;
char cIsShareStack;
void *pvEnv; //保存程序系统环境变量
//char sRunStack[ 1024 * 128 ];
stStackMem_t* stack_mem; //栈内存大小
//save satck buffer while confilct on same stack_buffer;
char* stack_sp;
unsigned int save_size;
char* save_buffer;
stCoSpec_t aSpec[1024];
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
协程存在 stackful 和 stackless 的两种技术:
| 特征 | stackful | stackless |
|---|---|---|
| 分配内存的位置 | 一个固定的栈内存 | 栈内存位置不固定 |
| 性能 | 中断返回需要依赖控制 CPU的跳转位置来实现 | 无影响 |
| 内存 | 分配一个固定大小的栈内存(如 4kb) | 只需创建带一个状态号变量的状态机 |
| 操作 | 可以轻松实现完全一致的递归/异常处理等,没有任何影响 | 需要编译器作者高超的技艺才能实现 |
| 挂起 | 可以在内部的嵌套函数中被挂起,在挂起点恢复执行 | 仅能在顶层部分被挂起 |
详细描述:
前者为每一个协程分配一个单独的、固定大小的栈;而后者则仅为正在运行的协程分配栈内存,当协程a被调度切换出去时,就把它实际占用的栈内存 copy 保存到一个单独分配的缓冲区;当被切出去的协程再次调度执行时,再一次 copy 将原来保存的栈内存恢复到那个共享的、固定大小的栈内存空间。通常情况下,一个协程实际占用的(从 esp 到栈底)栈空间,相比预分配的这个栈大小(比如 libco的 128KB)会小得多;这样一来,copyingstack 的实现方案所占用的内存便会少很多。当然,协程切换时拷贝内存的开销有些场景下也是很大的。因此两种方案各有利弊,而libco 则同时实现了两种方案,默认使用前者,也允许用户在创建协程时指定使用共享栈。
协程执行的环境:
struct stCoRoutineEnv_t
{
stCoRoutine_t *pCallStack[ 128 ]; //调用栈:如果将协程看成一种特殊的函数,那么这个 pCallStack 就时保存这些函数的调用链的栈。
int iCallStackSize;
stCoEpoll_t *pEpoll;
//for copy stack log lastco and nextco
stCoRoutine_t* pending_co;
stCoRoutine_t* occupy_co;
};
2
3
4
5
6
7
8
9
10
iCallStackSize:
- 每当启动一个协程(resume)时,就将它的协程控制块stCoRoutine_t 结构指针保存在 pCallStack 的“栈顶”,然后“栈指针”iCallStackSize 加 1,最后切换context 到待启动协程运行。
- 当协程要让出CPU(yield)时,就将它的 stCoRoutine_t 从 pCallStack 弹出,“栈指针”iCallStackSize 减 1,然后切换 context 到当前栈顶的协程(原来被挂起的调用者)恢复执行。
- “压栈”和“弹栈”的过程, 对应 co_resume() 和 co_yield() 函数
问题:libco 程序的第一个协程呢,假如第一个协程 yield 时,CPU控制权让给谁呢?
“第一个”协程是什么。实际上,libco 的第一个协程,即执行 main 函数的协程,是一个特殊的协程。这个协程又 可以称作主协程,它负责协调其他协程的调度执行(后文我们会看到,还有网络 I/O 以及定时事件的驱动),它自己 则永远不会 yield,不会主动让出 CPU。不让出(yield)CPU,不等于说它一直霸占着 CPU。
CPU 执行权有两种转移途径
- 通过 yield 让给调用者;
- resume 启动其他协程运行。
co_resume()与 co_yield() 都伴随着上下文切换,即 CPU控制流的转移。
当程序中第一次调用co_resume()时,CPU 执行权就从主协程转移到了 resume 目标协程上了。
问题:主协程是在什么时候创建出来的呢?什么时候 resume 的呢?
事实上,主协程是跟 stCoRoutineEnv_t 一起创建的。主协程也无需调用 resume 来启动,它就是程序本身,就是 main 函数。
主协程是一个特殊的存在,可以认为它只是一个结构体而已。在程序首次调用 co_create() 时,此函数内部会判断当前进程(线程)的 stCoRoutineEnv_t 结构是否已分 配,如果未分配则分配一个,同时分配一个 stCoRoutine_t 结构,并将 pCallStack[0] 指向主协程。此后如果用co_resume() 启动协程,又会将 resume 的协程压入 pCallStack 栈。
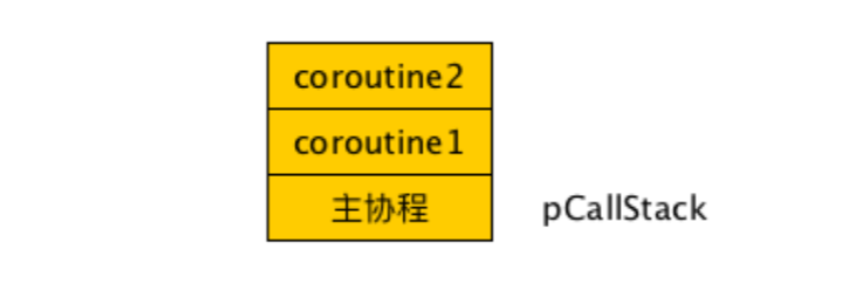
- coroutine2 整处于栈顶位置,是coroutine1 resume调用的;
- coroutine1 则是主协程 main resume调用的;
main 函数中程序最终调用了 co_eventloop()。该函数是一个基于epoll/kqueue 的事件循环,负责调度其他协程运行。(stCoRoutineEnv_t中的pEpoll在此使用)
libco的生命周期
常用函数:
int co_create( stCoRoutine_t **co,const stCoRoutineAttr_t *attr,void *(*routine)(void*),void *arg );
void co_resume( stCoRoutine_t *co );
void co_yield( stCoRoutine_t *co );
void co_yield_ct(); //ct = current thread
void co_release( stCoRoutine_t *co );
void co_reset(stCoRoutine_t * co);
2
3
4
5
6
创建协程
libco 中创建协程是 co_create() 函数。函数声明如下:
int co_create( stCoRoutine_t **co,const stCoRoutineAttr_t *attr,void *(*routine)(void*),void *arg );
@co: stCoRoutine_t** 类型的指针。输出参数,co_create 内部会为新协程分配 个“协程控制块”,co 将 指向这个分配的协程控制块。
@attr: stCoRoutineAttr_t 类型的指针。输入参数,用于指定要创建协程的属性,可为 NULL。实际上仅有两个 属性:栈大小、指向共享栈的指针(使用共享栈模式)。
@routine: void* (*)(void ) 类型的函数指针,指向协程的任务函数,即启动这个协程后要完成什么样的任 务。routine 类型为函数指针。
@arg: void 类型指针,传递给任务函数的参数,类似于 pthread 传递给线程的参数。调用 co_create 将协程 创建出来后,这时候它还没有启动,也即是说我们传递的routine 函数还没有被调用。
启动协程
在调用 co_create 创建协程返回成功后,便可以调用 co_resume 函数将它启动了。该函数声明如下::
void co_resume( stCoRoutine_t *co );
- @co: 启动co指针指向的协程,即co_create返回的第一个参数内容。
void co_resume( stCoRoutine_t *co )
{
stCoRoutineEnv_t *env = co->env; //获取协程执行的环境
stCoRoutine_t *lpCurrRoutine = env->pCallStack[ env->iCallStackSize - 1 ]; //获取栈顶,即当前协程控制块指针
/*
首次启动协程过程有点特殊,需要调用 coctx_make() 为新协程准备 context(为了让 co_swap() 内能跳转到协程的任务函数),
并将 cStart 标志变量置 1。
*/
if( !co->cStart )
{
coctx_make( &co->ctx,(coctx_pfn_t)CoRoutineFunc,co,0 );
co->cStart = 1;
}
env->pCallStack[ env->iCallStackSize++ ] = co; //将待启动的协程 co 压入 pCallStack 栈
co_swap( lpCurrRoutine, co ); //co_swap() 切换到 co 指向的新协程上去执行。
/*注意:co_swap不会就此返回,只有被调协程 yield 让出 CPU,调用者协程的co_swap() 函数才能返回到原
点,即返回到原来co_resume() 内的位置。整个过程是串行的。
*/
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
协程的挂起
调用 co_yield 函数,将CPU让给原来启动当前协程的调用者。该函数声明如下::
void co_yield( stCoRoutine_t *co )
具体函数:
void co_yield( stCoRoutine_t *co )
{
co_yield_env( co->env );
}
void co_yield_env( stCoRoutineEnv_t *env )
{
stCoRoutine_t *last = env->pCallStack[ env->iCallStackSize - 2 ];
stCoRoutine_t *curr = env->pCallStack[ env->iCallStackSize - 1 ];
env->iCallStackSize--;
co_swap( curr, last);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
找到当前协程的指针 和 上一个协程指针(调用者协程),完成两者的上下文切换,同时iCallStackSize -1
协程的切换
无论是 co_resume 还是 co_yield,核心内容都是切换 CPU 执行上下文,即完成协程的切换。
具体函数:
void co_swap(stCoRoutine_t* curr, stCoRoutine_t* pending_co)
{
...
//swap context
coctx_swap(&(curr->ctx),&(pending_co->ctx) );
...
}
extern "C"
{
extern void coctx_swap( coctx_t *,coctx_t* ) asm("coctx_swap");
};
coctx_swap.S 里
.globl coctx_swap
#if !defined( __APPLE__ )
.type coctx_swap, @function
#endif
coctx_swap:
#if defined(__i386__)
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
swap的实现原理:
用汇编,复制,保存寄存器中的值,改变CPU寄存器里面跳转下一个指令的地址,实现上下文切换,即改CPU下一行要执行的代码。
void coctx_swap( coctx_t* curr,coctx_t* pending) asm("coctx_swap");
coctx_swap 接受两个参数,无返回值。
- curr 为当前协程的 coctx_t结构指针,输出参数,函数调用过程中会将当前协程的 context 保存在这个参数指向的内存里;
- pending 为待切入的协程的 coctx_t 指针,输入参数,coctx_swap 从这里取上次保存的 context,恢复各寄存器的值。
coctx_t 结构:就是用于保存各寄存器值(context)的。
这个函数奇特之处,在于调用之前还处于第一个协程的环境,该函数返回后,则当前运行的协程就已经完全是第二个协程了。
协程的退出
调用 co_create()、co_resume()启动协程执行一次性任务,当任务结束后要记得调用co_free()或 co_release()销毁这个临时性的协程,否则将引起内存泄漏。
具体函数:
void co_release( stCoRoutine_t *co )
{
co_free( co );
}
2
3
4
事件驱动与协程调度
上面已经介绍了 libco 的协程从创建到启动,挂起、起动以及最后退出的过程。一个线程上的所有协程本质上是串行执行的。
在生产者和消费者的例子中:在 Producer 协程函数内我们会看到调用 poll函数等待 1 秒,Consumer中也会看到调用 co_cond_timedwait 函数等待生产者信号。
- 从协程的角度看,这些等待看起来都是同步的(synchronous),阻塞的(blocking);
- 但从底层线程的角度来看,则是非阻塞的(nonblocking)。
这跟 pthread 实现的原理是一样的。
- 在 pthread 实现的消费者中,你可能用 pthread_cond_timedwait 函数去同步等待生产者的信号;
- 在 生产者中,你可能用 poll 或 sleep 函数去定时等待。
从线程的角度看,这些函数都会让当前线程阻塞;但从内核的角度看,它本身并没有阻塞,内核可能要继续忙着调度别的线程运行。
那么这里协程也是一样的道理,从协程的角度看,当前的程序阻塞了;但从它底下的线程来看,自己可能正忙着执行别的协程函数。
在这个例子中,当 Consumer 协程调用 co_cond_timedwait 函数“阻塞”后,线程可能已经将 Producer 调度恢复执行。 反之亦然,那么这个负责协程“调度”的线程在哪呢?它即是运行协程本身的这个线程。
主协程和协程的调度
主协程在 co_eventloop() 函数里头忙活。这个 co_eventloop() 即“调度器”的核心所在。
基于 epoll/kqueue 事件驱动”的调度算法。“调度器”就是 epoll/kqueue 的事件循环。
stCoEpoll_t 结构与定时器
在分析 stCoRoutineEnv_t 结构的时候,还有一个 stCoEpoll_t 类型的pEpoll 指针成员没有讲到。
作为 stCoRoutineEnv_t 的成员,这个结构也是一个全局性的资源,被同一个线程上所有协程共享。从命名也 看得出来,stCoEpoll_t 是跟 epoll 的事件循环相关的。
内部字段:
struct stCoEpoll_t
{
int iEpollFd;
static const int _EPOLL_SIZE = 1024 * 10;
struct stTimeout_t *pTimeout;
struct stTimeoutItemLink_t *pstTimeoutList;
struct stTimeoutItemLink_t *pstActiveList;
co_epoll_res *result;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
- @iEpollFd: epoll 实例的事件描述符。
- @_EPOLL_SIZE: 值为 10240 的整型常量。作为 epoll_wait() 系统调用的第三个参数,即 epoll_wait最多返回的就绪事件个数。
- @pTimeout: 类型为 stTimeout_t 的结构体指针。该结构实际上是 个时间轮(Timingwheel)定时器
- @pstTimeoutList: 指向 stTimeoutItemLink_t 类型的结构体指针。该指针实际上是一个链表头。链表用于临时存放超时事件的 item。
- @pstActiveList: 指向 stTimeoutItemLink_t 类型的结构体指针。也是指向一个链表。该链表用于存放epoll_wait 得到的就绪事件和定时器超时事件。
- @result: 对 epoll_wait()第二个参数的封装,即epoll_wait 得到的结果集。
定时器是事件驱动模型的网络框架一个必不可少的功能。网络 I/O 的超时,定时任务,包括定时等待(poll 或 timedwait)都依赖于此。 一般而言,使用定时功能时,首先向定时器中注册一个定时事件(Timer Event),在注册定时事件时需要指定这个事件在未来的触发时间。 在到了触发时间点后,会收到定时器的通知。
网络框架里的定时器可以看做由两部分组成:
- 保存已注册 timer events的数据结构;
- 定时通知机制。
保存已注册的timer events,一般选用红黑树,比如 nginx;另外一种常见的数据结构便是时间轮,libco 就使用了这种结构。 当然也可以直接用链表来实现,只是时间复杂度比较高,在定时任务很多时会很容易成为框架的性能瓶颈。
int epoll_wait(int epfd,struct epoll_event * events, int maxevents,int timeout);
使用 epoll 加时间轮的实现定时器的算法如下:
- [epoll_wait]调用 epoll_wait() 等待 I/O 就绪事件,最长等待时长设置为 1 毫秒(即epoll_wait() 的第4个参数timeout)。
- [处理 I/O 就绪事件] 循环处理 epoll_wait() 得到的 I/O 就绪 件描述符。
- [从时间轮取超时事件] 从时间轮取超时事件,放到 timeout 队列。
- [处理超时事件] 如果 Step 3 取到的超时事件不为空,那么循环处理 timeout队列中的定时任务。否 则跳转到 Step 1 继续事件循环。
- [继续循环] 跳转到 Step 1,继续事件循环。
挂起协程与恢复的执行
实际上在 libco 中共有 3 种调用 yield 的场景:
- 用户程序中主动调用 co_yield_ct();
- 程序调用了 poll() 或 co_cond_timedwait() 陷 “阻塞”等待;
- 程序调用了 connect(), read(), write(), recv(), send() 等系统调用陷 “阻塞”等待。
相应地,重新resume 启动一个协程也有 3 种情况:
- 对应用户程序主动 yield 的情况,这种情况也有赖于用户程序主动将协程co_resume() 起来;
- poll() 的目标事件描述符事件就绪或超时,co_cond_timedwait() 等到了其他协程的 co_cond_signal() 通知信号或等待超时;
- read(), write() 等 I/O 接口成功读到或写入数据,或者读写超时。
三种情况分析
第一种情况,即用户主动 yield 和resume 协程,相当于 libco 的使用者承担了部分的协程“调度”工作。
第二种情况,即生产者消费者的例子。在那个例子中我们看不到用户程序主动调用 yield,也只有在最初启动协程时调用了 resume。生产者和消费者协程是在哪里切换的呢?在 poll() 与 co_cond_timedwait() 函数中。
消费者:当消费者协程首先启动时,它会发现任务队列是空的,于是调用co_cond_timedwait() 在条件变量 cond 上“阻塞”等待。同操作系统线程的条件等待原理一样,这里条件变量stCoCond_t 类型内部也有一个“等待队列”。 co_cond_timedwait() 函数内部会将当前协程挂入条件变量的等待队列上,并设置一个回调函数,该回调函数是用于未来“唤醒”当前协程的(即 resume 挂起的协程)。此外,如果wait 的 timeout 参数大于 0 的话,还要向当前执行环境
的定时器上注册一个定时事件(即挂到时间轮上)。在这个例子中,消费者协程co_cond_timedwait 的 timeout 参数为-1,即 indefinitly 地等待下去,直到等到生产者向条件变量发出 signal 信号。
生产者:当生产者协程启动后,它会向任务队列里投放一个任务并调用co_cond_signal() 通知消费者,然后再调用 poll() 在原地“阻塞”等待 1000 毫秒。这里co_cond_signal 函数内部其实也简单,就是将条件变量的等待队列里的协程拿出来,然后挂到当前执行环境的 pstActiveList。co_cond_signal函数并没有立即 resume 条件变量上的等待协程,毕竟这还不到交 出 CPU 的时机。那么什么时候交出 CPU 控制权,什么时候 resume 消费者协程呢?继续往下看,生产者在向消费者发出“信号”之后,紧接着便调用 poll() 进入了“阻塞”等待,等待 1 秒钟。 这个poll 函数内部实际上做了两件事。首先,将自己作为一个定时事件注册到当前执行环境的定时器,注册的时候设置了 1 秒钟的超时时间和一个回调函数(仍是一个用于未来“唤醒”自己的回调)。 然后,就调用 co_yield_env() 将 CPU 让给主协程了。现在,CPU 控制权又回到了主协程手中。主协程此时要干什么呢?我们已经讲过,主协程就是事件循环 co_eventloop() 函 数。在 co_eventloop() 中,主协程周而复始地调用epoll_wait(),当有就绪的 I/O 事件就处理 I/O 事件,当定时器上有超时的事件就处理超时事件,pstActiveList 队列中已有活跃事件就处理活跃事件。
这里所谓的“处理事件”,其实就是调用其他工作协程注册的各种回调函数而已。那么前面我们讲过,消费者协程和生产者协程的回调函数都是“唤醒”自己而已。 工作协程调用 co_cond_timedwait()或 poll() 陷入“阻塞”等待,本质上即是通过co_yield_env 函数让出了 CPU;而主协程则负责在事件循环中“唤醒”这些“阻塞”的协程,所谓“唤醒”操作即 调用工作协程注册的回调函数,这些回调内部使用 co_resume() 重新恢复挂起的工作协程。
第三种情况,即调用 read(), write() 等 I/O 操作而陷入“阻塞”和最后又恢复执行的过程。这种情况跟第二种过程基本相似。 需要注意的是,这里的“阻塞”依然是用户态实现的过程。我们知道,libco 的协程是在底层线程上串行执行的。 如果调用 read 或 write 等系统调用陷入真正的阻塞(让当前线程被内核挂起) 的话,那么不光当前协程被挂起了,其他协程也得不到执行的机会。 因此,如果工作协程陷入真正的内核态阻塞,那么 libco 程序就会完全停止运转,后果是很严重的。为了避免陷入内核态阻塞, 我们必须得依靠内核提供的非阻塞 I/O 机制,将socket文件描述符设置为 non-blocking 的。为了让 libco 的使用者更方便,我们还得将这种non-blocking 的过 程给封装起来,伪装成“同步阻塞式”的调用(跟 co_cond_timedwait()一样)。事实上,go 语言就是这么做的。而 libco 则将这个过程伪装得更加彻底,更加具有欺骗性。 它通过dlsym机制 hook 了各种网络 I/O 相关的系统调用,使得用户可以以“同步”的方式直接使用诸如read()、write()和connect()等系统调用。因此,我们会看到生产者消费者协程任务 函数里第一句就调用了一个 co_enable_hook_sys()的函数。调用了co_enable_hook_sys 函数才会开启 hook 系统调用功能,并且需要事先将要读写的文件描述符设置为 non-blocking 属性, 否则,工作协程就可能陷入真正的内核态阻塞,这一点在应用中要特别加以注意。 以 read() 为 例,让我们再来分析一下这些“伪装”成同步阻塞式系统调用的内部原理。首先,假如程序 accept 了一个新连接, 那么首先我们将这个连接的 socket 文件描述符设置为非阻塞模式,然后启动一个工作协程去处理这个连接。工作协 程调用 read()试图从该新连接上读取数据。这时候由于系统 read() 函数已经被 hook,所以实际上会调用到 libco 内部准备好的read() 函数。这个函数内部实际上做了 4 件事:
- 第一步:将当前协程注册到定时器上,用于将来处理 read() 函数的读超时。
- 第二步:调用 epoll_ctl()将自己注册到当前执行环境的 epoll 实例上。这两步注册 过程都需要指定一个回调函数,将来用于“唤醒”当前协程。
- 第三步:调用 co_yield_env 函数让出 CPU。
- 第四步:要等到该协程被主协程重新“唤醒”后才能继续。如果主协程 epoll_wait() 得知 read 操作的文件描述符可读,则会 执行原 read 协程注册的会回调将它唤醒(超时后同理,不过还要设置超时标志)。工作协程被唤醒后,在调用原 glibc 内被 hook 替换掉的、真正的 read() 系统调用。这时候如果是正常 epoll_wait 得知文件描述符 I/O 就 绪就会读到数据,如果是超时就会返回-1。总之,在外部使用者看来,这个 read() 就跟阻塞式的系统调用表现出几 乎完全一致的行为了
主协程事件循环源码分析
源码程序:
void co_eventloop( stCoEpoll_t *ctx,pfn_co_eventloop_t pfn,void *arg )
{
if( !ctx->result )
{
ctx->result = co_epoll_res_alloc( stCoEpoll_t::_EPOLL_SIZE );
}
co_epoll_res *result = ctx->result;
for(;;)
{
int ret = co_epoll_wait( ctx->iEpollFd,result,stCoEpoll_t::_EPOLL_SIZE, 1 );//调用 epoll_wait() 等待I/O就绪事件,为了配合时间轮工作,timeout设置为1毫秒。
stTimeoutItemLink_t *active = (ctx->pstActiveList); //active 指针指向当前执行环境的 pstActiveList 队列,即“活跃”的待处理事件。
stTimeoutItemLink_t *timeout = (ctx->pstTimeoutList); //timeout 指针指向 pstTimeoutList 列表,即定时器上的超时事件。
memset( timeout,0,sizeof(stTimeoutItemLink_t) );
/*
处理就绪的事件描述符。如果用户设置了预处理回调,则调用pfnPrepare 做预处理;否则
直接将就绪事件 item 加 active 队列。实际上,pfnPrepare() 预处理函数内部也会将就绪 item 加 active 队
列,最终都是加 到 active队列等到 32~40 统一处理。
*/
for(int i=0;i<ret;i++)
{
stTimeoutItem_t *item = (stTimeoutItem_t*)result->events[i].data.ptr;
if( item->pfnPrepare )
{
item->pfnPrepare( item,result->events[i],active );
}
else
{
AddTail( active,item );
}
}
unsigned long long now = GetTickMS();
TakeAllTimeout( ctx->pTimeout,now,timeout ); //从时间轮上取出已超时的事件,放到timeout队列。
//遍历 timeout 队列,设置事件已超时标志(bTimeout 设为 true)
stTimeoutItem_t *lp = timeout->head;
while( lp )
{
//printf("raise timeout %p\n",lp);
lp->bTimeout = true;
lp = lp->pNext;
}
Join<stTimeoutItem_t,stTimeoutItemLink_t>( active,timeout );//将 timeout 队列中事件合并到 active 队列。
/*
遍历 active 队列,调用 作协程设置的 pfnProcess() 回调函数 resume挂起的 作协程,处理对
应的 I/O 或超时事件。这就是主协程的事件循环工作过程,我们看到它周而复始地 epoll_wait(),唤醒挂起的工作
协程去处理定时器与 I/O 事件。这里的逻辑看起来跟所有基于 epoll 实现的事件驱动网络框架并没有什么特别之
处,更没有涉及到任何协程调度算法,由此也可以看到 libco 其实是一个很典型的非对称协程机制。或许,从
call/return 的角度出发,而不是 resume/yield 去理解这种协程的运行机理,反而会有更深的理解吧
*/
lp = active->head;
while( lp )
{
PopHead<stTimeoutItem_t,stTimeoutItemLink_t>( active );
if (lp->bTimeout && now < lp->ullExpireTime)
{
int ret = AddTimeout(ctx->pTimeout, lp, now);
if (!ret)
{
lp->bTimeout = false;
lp = active->head;
continue;
}
}
if( lp->pfnProcess )
{
lp->pfnProcess( lp );
}
lp = active->head;
}
if( pfn )
{
if( -1 == pfn( arg ) )
{
break;
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91