架构设计原则 - DDD领域驱动设计:贫血模型和充血模型
参考资料
贫血模型
贫血模型是指使用的领域对象中只有setter和getter方法(POJO),所有的业务逻辑都不包含在领域对象中而是放在业务逻辑层。
贫血模型下组织领域逻辑通常使用事务脚本模式,让每个过程对应用户可能要做的一个动作,每个动作由一个过程来驱动。也就是说在设计业务逻辑接口的时候,每个方法对应着用户的一个操作,这种模式有以下几个优点:
- 它是一个大多数开发者都能够理解的简单过程模型
- 它能够与一个使用行数据入口或表数据入口的简单数据访问层很好的协作。
- 事务边界的显而易见,一个事务开始于脚本的开始,终止于脚本的结束,很容易通过代理(或切面)实现声明式事务。
然而,事务脚本模式的缺点也是很多的,随着领域逻辑复杂性的增加,系统的复杂性将迅速增加,程序结构将变得极度混乱。
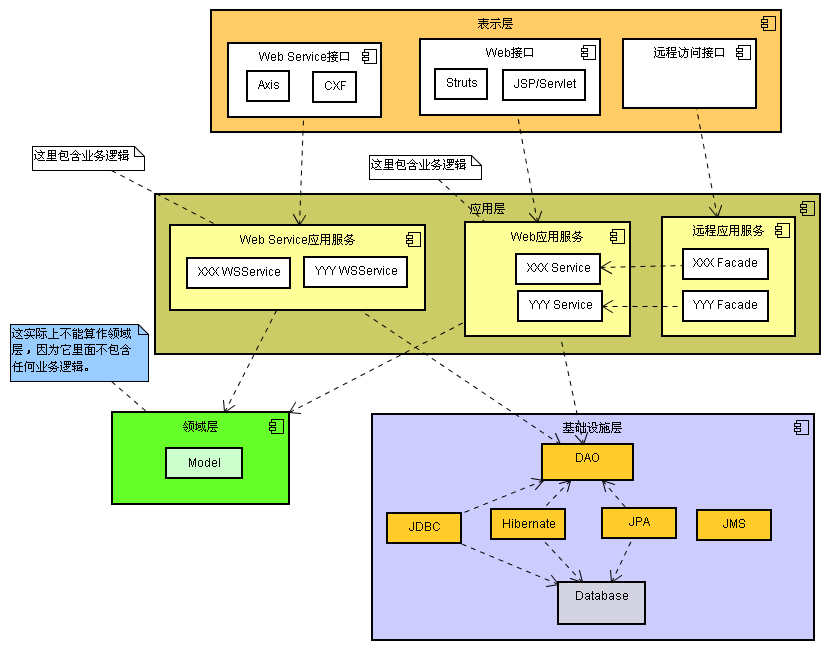
贫血模型实施的最大难度在于如何梳理好Business Logic层内部的划分关系,由于该层会比较庞大,边界不易控制,内部的各个模块之间的依赖关系不易管理,可以考虑这样这样的实现思路:
- 铺设扁平的原子业务逻辑层,即简单的CRUD操作(含批量数据操作);
- 特定业务清晰的逻辑通过Facade层来组装原子操作实现。
- 给业务逻辑层实施模块划分,保持模块之间的松耦合的关系。
充血模型
充血模型将大多数业务逻辑和持久化放在领域对象中,业务逻辑只是完成对业务逻辑的封装、事务和权限等的处理。
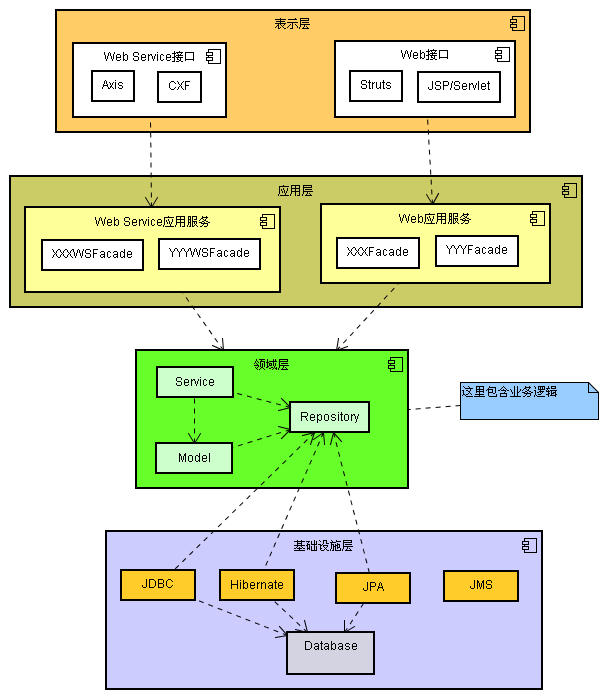
充血模型的优点是面向对象,Business Logic符合单一职责,不像在贫血模型里面那样包含所有的业务逻辑太过沉重。缺点是如何划分业务逻辑,什么样的逻辑应该放在Domain Object中,什么样的业务逻辑应该放在Business Logic中,这是很含糊的。
充血模型的层次和模块的划分是一门学问,对开发人员要求亦较高,可以考虑定义这样的一些规则:
- 事务控制不要放在领域模型的对象中实现,可以放在facade(外观模式)中完成。
- 领域模型对象中只保留该模型驱动的一般方法,对于业务特征明显的特异场景方法调用放在facade(外观模式)中完成。
对比分析
为什么基于贫血模型的传统开发模式如此受欢迎?
基于贫血模型的传统开发模式,将数据与业务逻辑分离,违反了 OOP 的封装特性,实际上是一种面向过程的编程风格。但是,现在几乎所有的 Web 项目,都是基于这种贫血模型的开发模式,甚至连 Java Spring 框架的官方 demo,都是按照这种开发模式来编写的。
面向过程编程风格有种种弊端,比如,数据和操作分离之后,数据本身的操作就不受限制了。任何代码都可以随意修改数据。既然基于贫血模型的这种传统开发模式是面向过程编程风格的,那它又为什么会被广大程序员所接受呢?
关于这个问题,主要是有下面三点原因。
大部分情况下,我们开发的系统业务可能都比较简单,简单到就是基于 SQL 的 CRUD 操作。所以,根本不需要动脑子精心设计充血模型,贫血模型就足以应付这种简单业务的开发工作。除此之外,因为业务比较简单,即便使用充血模型,那模型本身包含的业务逻辑也并不会很多,设计出来的领域模型也会比较单薄,跟贫血模型差不多,没有太大意义。
充血模型的设计要比贫血模型更加有难度。因为充血模型是一种面向对象的编程风格。我们从一开始就要设计好针对数据要暴露哪些操作,定义哪些业务逻辑。而不是像贫血模型那样,只需要定义数据,之后有什么功能开发需求,就在 Service 层定义什么操作,不需要事先做太多设计。
思维已固化,转型有成本。基于贫血模型的传统开发模式经历了这么多年,已经深得人心、习以为常。如果转向用充血模型、领域驱动设计,那势必有一定的学习成本、转型成本。很多人在没有遇到开发痛点的情况下,是不愿意做这件事情的。
什么项目应该考虑使用基于充血模型的 DDD 开发模式?
相对应的,基于充血模型的 DDD 开发模式,更适合业务复杂的系统开发。比如,包含各种利息计算模型、还款模型等复杂业务的金融系统。
你可能会有一些疑问,这两种开发模式,落实到代码层面,区别不就是一个将业务逻辑放到 Service 类中,一个将业务逻辑放到 Domain 领域模型中吗?为什么基于贫血模型的传统开发模式,就不能应对复杂业务系统的开发?而基于充血模型的 DDD 开发模式就可以呢?
实际上,除了我们能看到的代码层面的区别之外(一个业务逻辑放到 Service 层,一个放到领域模型中),还有一个非常重要的区别,那就是两种不同的开发模式会导致不同的开发流程。基于充血模型的 DDD 开发模式的开发流程,在应对复杂业务系统的开发的时候更加有优势。为什么这么说呢?我们先来回忆一下,我们平时基于贫血模型的传统的开发模式,都是怎么实现一个功能需求的。
不夸张地讲,平时的开发,大部分都是 SQL 驱动(SQL-Driven)的开发模式。接到一个后端接口的开发需求的时候,就去看接口需要的数据对应到数据库中,需要哪张表或者哪几张表,然后思考如何编写 SQL 语句来获取数据。之后就是定义 Entity、BO、VO,然后模板式地往对应的 Repository、Service、Controller 类中添加代码。
业务逻辑包裹在一个大的 SQL 语句中,而 Service 层可以做的事情很少。SQL 都是针对特定的业务功能编写的,复用性差。当要开发另一个业务功能的时候,只能重新写个满足新需求的 SQL 语句,这就可能导致各种长得差不多、区别很小的 SQL 语句满天飞。
所以,在这个过程中,很少有人会应用领域模型、OOP 的概念,也很少有代码复用意识。对于简单业务系统来说,这种开发方式问题不大。但对于复杂业务系统的开发来说,这样的开发方式会让代码越来越混乱,最终导致无法维护。
如果我们在项目中,应用基于充血模型的 DDD 的开发模式,那对应的开发流程就完全不一样了。在这种开发模式下,我们需要事先理清楚所有的业务,定义领域模型所包含的属性和方法。领域模型相当于可复用的业务中间层。新功能需求的开发,都基于之前定义好的这些领域模型来完成。